北京时间2024年1月23日,KubeEdge发布1.16版本。新版本新增多个增强功能,在集群升级、集群易用性、边缘设备管理等方面均有大幅提升。
KubeEdge v1.16 新增特性:
- 集群升级:支持云边组件自动化升级
- 支持边缘节点的镜像预下载
- 支持使用Keadm安装Windows边缘节点
- 增加多种容器运行时的兼容性测试
- EdgeApplication中支持更多Deployment对象字段的Override
- 支持基于Mapper-Framework的Mapper升级
- DMI数据面内置集成Redis与TDEngine数据库
- 基于Mapper-Framework的USB-Camera Mapper实现
- 易用性提升:基于Keadm的部署能力增强
- 升级K8s依赖到v1.27
新特性概览
集群升级:支持云边组件自动化升级
随着KubeEdge社区的持续发展,社区版本不断迭代;用户环境版本升级的诉求亟需解决。针对升级步骤难度大,边缘节点重复工作多的问题,v1.16.0版本的 KubeEdge 支持了云边组件的自动化升级。用户可以通过Keadm工具一键化升级云端,并且可以通过创建相应的Kubernetes API,批量升级边缘节点。
云端升级
云端升级指令使用了三级命令与边端升级进行了区分,指令提供了让用户使用更便捷的方式来对云端的KubeEdge组件进行升级。当前版本升级完成后会打印ConfigMap历史配置,如果用户手动修改过ConfigMap,用户可以选择通过历史配置信息来还原配置文件。我们可以通过help参数查看指令的指导信息:
keadm upgrade cloud --help
Upgrade the cloud components to the desired version, it uses helm to upgrade the installed release of cloudcore chart, which includes all the cloud components
Usage:
keadm upgrade cloud [flags]
Flags:
--advertise-address string Please set the same value as when you installed it, this value is only used to generate the configuration and does not regenerate the certificate. eg: 10.10.102.78,10.10.102.79
-d, --dry-run Print the generated k8s resources on the stdout, not actual execute. Always use in debug mode
--external-helm-root string Add external helm root path to keadm
--force Forced upgrading the cloud components without waiting
-h, --help help for cloud
--kube-config string Use this key to update kube-config path, eg: $HOME/.kube/config (default "/root/.kube/config")
--kubeedge-version string Use this key to set the upgrade image tag
--print-final-values Print the final values configuration for debuging
--profile string Sets profile on the command line. If '--values' is specified, this is ignored
--reuse-values reuse the last release's values and merge in any overrides from the command line via --set and -f.
--set stringArray Sets values on the command line (can specify multiple or separate values with commas: key1=val1,key2=val2)
--values stringArray specify values in a YAML file (can specify multiple)升级指令样例:
keadm upgrade cloud --advertise-address=<init时设置的值> --kubeedge-version=v1.16.0边端升级
v1.16.0版本的KubeEdge支持通过NodeUpgradeJob的Kubernetes API进行边缘节点的一键化、批量升级。API支持边缘节点的升级预检查、并发升级、失败阈值、超时处理等功能。对此,KubeEdge支持了云边任务框架。社区开发者将无需关注任务控制、状态上报等逻辑实现,只需聚焦云边任务功能本身。
升级API样例:
apiVersion: operations.kubeedge.io/v1alpha1
kind: NodeUpgradeJob
metadata:
name: upgrade-example
labels:
description: upgrade-label
spec:
version: "v1.16.0"
checkItems:
- "cpu"
- "mem"
- "disk"
failureTolerate: "0.3"
concurrency: 2
timeoutSeconds: 180
labelSelector:
matchLabels:
"node-role.kubernetes.io/edge": ""
node-role.kubernetes.io/agent: ""兼容测试
KubeEdge社区提供了完备了版本兼容性测试,用户在升级时仅需要保证云边版本差异不超过2个版本,就可以避免升级期间云边版本不一致带来的问题。
更多信息可参考:
https://github.com/kubeedge/kubeedge/pull/5330 https://github.com/kubeedge/kubeedge/pull/5229 https://github.com/kubeedge/kubeedge/pull/5289
支持边缘节点的镜像预下载
新版本引入了镜像预下载新特性,用户可以通过ImagePrePullJob的Kubernetes API提前在边缘节点上加载镜像,该特性支持在批量边缘节点或节点组中预下载多个镜像,帮助减少加载镜像在应用部署或更新过程,尤其是大规模场景中,带来的失败率高、效率低下等问题。
镜像预下载API示例:
apiVersion: operations.kubeedge.io/v1alpha1
kind: ImagePrePullJob
metadata:
name: imageprepull-example
labels:
description:ImagePrePullLabel
spec:
imagePrePullTemplate:
images:
- image1
- image2
nodes:
- edgenode1
- edgenode2
checkItems:
- "disk"
failureTolerate: "0.3"
concurrency: 2
timeoutSeconds: 180
retryTimes: 1
更多信息可参考:
https://github.com/kubeedge/kubeedge/pull/5310 https://github.com/kubeedge/kubeedge/pull/5331
支持使用Keadm安装Windows边缘节点
KubeEdge 1.15版本实现了在Windows上运行边缘节点,在新版本中,我们支持使用安装工具Keadm直接安装Windows边缘节点,操作命令与Linux边缘节点相同,简化了边缘节点的安装步骤。
更多信息可参考:
https://github.com/kubeedge/kubeedge/pull/4968
增加多种容器运行时的兼容性测试
新版本中新增了多种容器运行时的兼容性测试,目前已集成了containerd,docker,isulad和cri-o 4种主流容器运行时,保障KubeEdge版本发布质量,用户在安装容器运行时过程中也可以参考该PR中的适配安装脚本。
更多信息可参考:
https://github.com/kubeedge/kubeedge/pull/5321
EdgeApplication中支持更多Deployment对象字段的Override
在新版本中,我们扩展了EdgeApplication中的差异化配置项(overriders),主要的扩展有环境变量、命令参数和资源。当您不同区域的节点组环境需要链接不同的中间件时,就可以使用环境变量(env)或者命令参数(command, args)去重写中间件的链接信息。或者当您不同区域的节点资源不一致时,也可以使用资源配置(resources)去重写cpu和内存的配置。
更多信息可参考:
https://github.com/kubeedge/kubeedge/pull/5262 https://github.com/kubeedge/kubeedge/pull/5370
支持基于Mapper-Framework的Mapper升级
1.16版本中,基于Mapper开发框架Mapper-Framework构建了Mapper组件的升级能力。新框架生成的Mapper工程以依赖引用的方式导入原有Mapper-Framework的部分功能,在需要升级时,用户能够以升级依赖版本的方式完成,简化Mapper升级流程。
Mapper-Framework代码解耦:
1.16版本中将Mapper-Framework中的代码解耦为用户层和业务层。用户层功能包括设备驱动及与之强相关的部分管理面数据面能力,仍会随Mapper-Framework生成在用户Mapper工程中,用户可根据实际情况修改。业务层功能包括Mapper向云端注册、云端下发Device列表等能力,会存放在kubeedge/mapper-framework子库中。
Mapper升级框架:
1.16版本Mapper-Framework生成的用户Mapper工程通过依赖引用的方式使用kubeedge/mapper-framework子库中业务层功能,实现完整的设备管理功能。后续用户能够通过升级依赖版本的方式达到升级Mapper的目的,不再需要手动修改大范围代码。
更多信息可参考:
https://github.com/kubeedge/kubeedge/pull/5308 https://github.com/kubeedge/kubeedge/pull/5326
DMI数据面内置集成Redis与TDEngine数据库
1.16版本中进一步增强DMI数据面中向用户数据库推送数据的能力,增加Redis与TDengine数据库作为内置数据库。用户能够直接在device-instance配置文件中定义相关字段,实现Mapper自动向Redis与TDengine数据库推送设备数据的功能,相关数据库字段定义为:
type DBMethodRedis struct {
// RedisClientConfig of redis database
// +optional
RedisClientConfig *RedisClientConfig `json:"redisClientConfig,omitempty"`
}
type RedisClientConfig struct {
// Addr of Redis database
// +optional
Addr string `json:"addr,omitempty"`
// Db of Redis database
// +optional
DB int `json:"db,omitempty"`
// Poolsize of Redis database
// +optional
Poolsize int `json:"poolsize,omitempty"`
// MinIdleConns of Redis database
// +optional
MinIdleConns int `json:"minIdleConns,omitempty"`
}
type DBMethodTDEngine struct {
// tdengineClientConfig of tdengine database
// +optional
TDEngineClientConfig *TDEngineClientConfig `json:"TDEngineClientConfig,omitempty"`
}
type TDEngineClientConfig struct {
// addr of tdEngine database
// +optional
Addr string `json:"addr,omitempty"`
// dbname of tdEngine database
// +optional
DBName string `json:"dbName,omitempty"`
}
更多信息可参考:
https://github.com/kubeedge/kubeedge/pull/5064
基于Mapper-Framework的USB-Camera Mapper实现
基于KubeEdge的Mapper-Framework,新版本提供了USB-Camera的Mapper样例,该Mapper根据USB协议的Camera开发,用户可根据该样例和Mapper-Framework更轻松地开发具体业务相关的Mapper。
在样例中提供了helm chart包,用户可以通过修改usbmapper-chart/values.yaml部署UBS-Camera Mapper,主要添加USB-Camera的设备文件, nodeName, USB-Camera的副本数,其余配置修改可根据具体情况而定,通过样例目录中的Dockerfile制作Mapper镜像。
global:
replicaCounts:
......
cameraUsbMapper:
replicaCount: 2 #USB-Camera的副本数
namespace: default
......
nodeSelectorAndDevPath:
mapper:
- edgeNode: "edgenode02" #USB-Camera连接的缘节点nodeName
devPath: "/dev/video0" #USB-Camera的设备文件
- edgeNode: "edgenode1"
devPath: "/dev/video17"
......
USB-Camera Mapper的部署命令如下:
helm install usbmapper-chart ./usbmapper-chart
更多信息可参考:
https://github.com/kubeedge/mappers-go/pull/122
易用性提升:基于Keadm的部署能力增强
添加云边通信协议配置参数
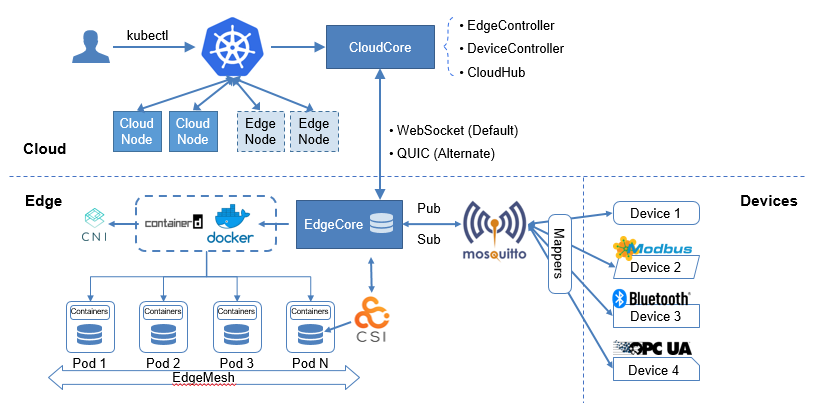
在KubeEdge v1.16.0中,使用keadm join边缘节点时,支持使用--hub-protocol配置云边通信协议。目前KubeEdge支持websocket和quic两种通信协议,默认为websocket协议。
命令示例:
keadm join --cloudcore-ipport <云节点ip>:10001 --hub-protocol=quic --kubeedge-version=v1.16.0 --token=xxxxxxxx说明:当--hub-protocol设置为quic时,需要将--cloudcore-ipport的端口设置为10001,并需在CloudCore的ConfigMap中打开quic开关,即设置modules.quic.enable为true。
操作示例:使用kubectl edit cm -n kubeedge cloudcore,将quic的enable属性设置成true,保存修改后重启CloudCore的pod。
modules:
......
quic:
address: 0.0.0.0
enable: true #quic协议开关
maxIncomingStreams: 10000
port: 10001更多信息可参考:
keadm join与CNI插件解耦
在新版本中,keadm join边缘节点时,不需要再提前安装CNI插件,已将边缘节点的部署与CNI插件解耦。同时该功能已同步到v1.12及更高版本,欢迎用户使用新版本或升级老版本。
说明:如果部署在边缘节点上的应用程序需要使用容器网络,则在部署完edgecore后仍然需要安装CNI插件。
更多信息可参考:
升级K8s依赖到v1.27
新版本将依赖的Kubernetes版本升级到v1.27.7,您可以在云和边缘使用新版本的特性。
更多信息可参考:
https://github.com/kubeedge/kubeedge/pull/5121
版本升级注意事项
新版本我们使用DaemonSet来管理边端的MQTT服务Eclipse Mosquitto了,我们能够通过云端Helm Values配置来设置是否要开启MQTT服务。使用DaemonSet管理MQTT后,我们可以方便的对边端MQTT进行统一管理,比如我们可以通过修改DaemonSet的配置将边端MQTT替换成EMQX。
但是如果您是从老版本升级到最新版本,则需要考虑版本兼容问题,同时使用原本由静态Pod管理的MQTT和使用新的DaemonSet管理的MQTT会产生端口冲突。兼容操作步骤参考:
- 您可以在云端执行命令,将旧的边缘节点都打上自定义标签
kubectl label nodes --selector=node-role.kubernetes.io/edge without-mqtt-daemonset=""
- 您可以修改MQTT DaemonSet的节点亲和性
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- ...
- key: without-mqtt-daemonset
operator: Exists
- 将节点MQTT改为由DaemonSet管理
# ------ 边端 ------
# 修改/lib/systemd/system/edgecore.service,将环境变量DEPLOY_MQTT_CONTAINER设置成false
# 这步可以放在更新EdgeCore前修改,这样就不用重启EdgeCore了
sed -i '/DEPLOY_MQTT_CONTAINER=/s/true/false/' /etc/systemd/system/edgecore.service
# 停止EdgeCore
systemctl daemon-reload && systemctl stop edgecore
# 删除MQTT容器,Containerd可以使用nerdctl替换docker
docker ps -a | grep mqtt-kubeedge | awk '{print $1}' | xargs docker rm -f
# 启动EdgeCore
systemctl start edgecore
# ------ 云端 ------
# 删除节点标签
kubectl label nodes <NODE_NAME> without-mqtt-daemonset
新版本的keadm join命令会隐藏with-mqtt参数,并且将默认值设置成false,如果您还想使用静态Pod管理MQTT,您仍然可以设置参数--with-mqtt来使其生效。with-mqtt参数在v1.18版本中将会被移除。